
 Eddie Kwon - Development log for ML, iOS
Eddie Kwon - Development log for ML, iOS
selenium, Scrapy links
10 Sep 2018 |각종 셀레니움 강좌나 링크
네이버 로그인등: https://beomi.github.io/2017/02/27/HowToMakeWebCrawler-With-Selenium/
위 사이트의 code snippet중 하나는 다음과 같다.
from selenium import webdriver
from bs4 import BeautifulSoup
# setup Driver|Chrome : 크롬드라이버를 사용하는 driver 생성
driver = webdriver.Chrome('/Users/beomi/Downloads/chromedriver')
driver.implicitly_wait(3) # 암묵적으로 웹 자원을 (최대) 3초 기다리기
# Login
driver.get('https://nid.naver.com/nidlogin.login') # 네이버 로그인 URL로 이동하기
driver.find_element_by_name('id').send_keys('naver_id') # 값 입력
driver.find_element_by_name('pw').send_keys('mypassword1234')
driver.find_element_by_xpath(
'//*[@id="frmNIDLogin"]/fieldset/input'
).click() # 버튼클릭하기
driver.get('https://order.pay.naver.com/home') # Naver 페이 들어가기
html = driver.page_source # 페이지의 elements모두 가져오기
soup = BeautifulSoup(html, 'html.parser') # BeautifulSoup사용하기
notices = soup.select('div.p_inr > div.p_info > a > span')
for n in notices:
print(n.text.strip())
구글 결과를 가져오는 사이트
https://medium.com/@peteryun/python-selenium을-활용한-크롤러-만들기-b055cefd1195
아래 wiki를 크롤링함

네이버 로그인 참고 사이트 http://yumere.tistory.com/75

소방방재청 자료 가져오기?
https://medium.com/@nsh235482/python-selenium으로-웹사이트-크롤링하기-2-웹-사이트-제어해보기-1ffc5e05179d
유튜브 줄줄이 크롤링
http://code-ing.tistory.com/6
셀레니움 기본
https://medium.com/shakuro/adopting-ipython-jupyter-for-selenium-testing-d02309dd00b8

네이버 뉴스 수집을 위한 도구 https://forkonlp.github.io/N2H4/
네이버 api 사용 https://ericnjennifer.github.io/python_crawling/2018/01/21/PythonCrawling_Chapt9.html
Scrapy URLs
scrapy data 저장 으로 검색하면 수 많은 강좌가 뜬다.
크롤링 후 firebase에 저장하기
https://medium.com/@wayfinders/scrapy를-활용한-crawler를-만든-후-firebase-database에-저장하기-a73f4e4ab70d
웹사이트 크롤링해서 파일 저장 하기(분양정보수집사례)
[U’s Lifelog]http://uslifelog.tistory.com/45
아래도 최신 정보가 많다
https://l0o02.github.io/2018/06/19/python-scrapy-1/
Scrapy를 이용한 뉴스 크롤링 하기
http://excelsior-cjh.tistory.com/86
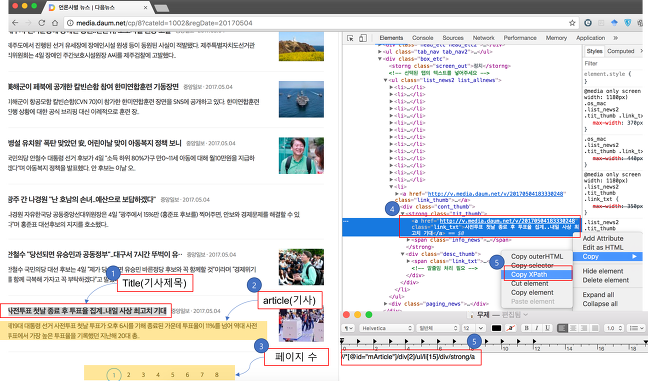
스크래핑개념 & 셀레니움
http://nittaku.tistory.com/133?category=727207
http://nittaku.tistory.com/136
XPATH에 대한 여러가지 예제도 있다. pipeline설명도 있다.
좋은 그림

기타
pycharm 세팅법들
http://nittaku.tistory.com/category/빅데이터%20관련%20프로그래밍/웹%20크롤링%20-%20기초
Comments